はじめに
セキュリティの分野などでよく知られている敵対的攻撃(adversarial attacks)は,機械学習モデルなどに対して,望ましくない出力をするように仕掛けることです.
多くの既存研究は,主に画像データに対するものです.有名なものとしては,Fast Gradient Sign Method(FGSM)が挙げられるでしょう.これはパンタの画像に対して,勾配に基づく適切なノイズを与えることで,別のクラスであるテナガザルに誤認させるというものです.

直感的なイメージとしては,モデルに対して勾配を利用して損失を減少させるのがモデルの訓練ですが,その逆を行うのがFGSMです.
しかし,テキストの場合,このような方法を直接利用することは少し難しいです.主な理由はテキストの離散性にあります.画像データは連続的なので,ノイズを生成することが簡単ですが,テキストでは難しいでしょう.
[Zhang+ ACL 2019]の概要では,離散性,知覚性,意味性にあると述べられています.離散性はさっきの話で,知覚性は入力の変化が人間から見るとわかりやすいという話で,意味性は文法や文の意味が根本的に変わってしまうという問題です.
前提として,本稿で扱う手法は,学習済みモデルに対する攻撃を扱います.つまり,モデルの重みは固定されていて,更新できないというシナリオを考えます.そのため,モデルパラメータ を省略して,
などを
と書きます.逆に直感的でない場合は引数を明示的に書きます.
本稿で扱うのは,主に次の勾配による攻撃と,脱獄プロンプトを扱います.本当はもっといろいろ分類があるので,詳しく知りたい人は適当なSoK論文を参照してください.
勾配攻撃(gradient attack)
前提として,勾配攻撃はモデルの中身がわかっているホワイトボックスなシナリオを想定します.なので,この手法はOSSのLLMなどには有効でしょう.例えば,OpenAIのChatGPTをはじめとするモデルはAPIを通じてアクセスしているので,重みなどの内部情報は「closed」になっています.このようなシナリオを,ホワイトボックスとは反対にブラックボックスと言います.
勾配攻撃(gradient attack)は簡単には、ある入力に対する損失の勾配をうまいこと利用して,モデルの出力を望ましくないように誘導する手法です.これは導入にも書きましたが,手法の問題点は,導入で述べたテキストの離散性にあります.なので,まずこれを解消する必要があります.
簡単な方法として,ガンベル分布を使って近似するという方法[Guos+ 2021] があります.論文内では,Gradient-based Distributional Attack(GBDA)と呼ばれています.一般的にこの近似方法は,ガンベル最大トリック(gumbel-max trick)として知られているので,数学的な詳細は次の記事が参考になります.
まず,トークンの選択をカテゴリカル分布からのサンプリングだと考えます.形式的に書くと,入力トークン列 はカテゴリカル分布
からサンプリングされ,分布は次のように書けます.
ただし, は語彙数です.
このとき,カテゴリカル分布は離散分布なので,サンプリングも微分不可能な操作です.そのため,これを連続分布であるガンベル分布を使って近似します.
[Guos+ 2021] での,敵対的損失関数は,次の通りです.ただし,モデル出力の品質を維持するために,流暢性のための負の対数尤度(NLL)とBERTScoreが考慮されています.NLLを最小化するということは,モデルの分布がデータの分布に近づくように学習することです.これはKLダイバージェンスを最小化することと等価です.具体的には,展開したときの一項目を定数と見做して,二項目がNLLの期待値に相当します.これを考えると,NLLを使うということが見通し良くなると思います.
GBDAの限界としては,トークンの追加・削除ができないので,置換操作しかできないという問題があります.
次にHot-Flip [Ebrahimi+ ACL 2018] と呼ばれるものです.敵対的損失関数をテイラー展開で一次近似します.
これを最適化するため,ベクトルを一つ選んで変更して,一度だけ誤差逆伝播法でパラメータ更新します.
Universal Adversarial Triggers(UAT)[Wallace+ EMNLP 2019] は,モデルのNext Token Predictionを特定の方向に誘導するような,接頭辞や接尾辞などの短いトークン列を勾配を用いた探索をするための手法です.
やや見慣れない記法かもしれませんが, は,データ分布
からサンプリングされた入力
に最適化するトークン
を結合するという意味です.[Wallace+ EMNLP 2019] 内では,トークン
をトリガー,
をトリガー付きトークンと呼んでいます.これを次のように目的関数に基づいて,最適化します.
見た目は難しいですが,要するに目標とするダミークラス に寄せるように
を探索するというのを式で書いただけです.具体的な
はケースバイケースでタスクごとに異なります.例えば,分類などではクロスエントロピー誤差を使うので,論文内の実験ではそれをもとに損失関数を用意していました.
これをHot Flipを利用しながら探索します.基本的なアイディアは勾配法ですが,語彙空間中――有限集合の中を離散的に探索するという点に注意してください.実際の動きは下の図を見てください.
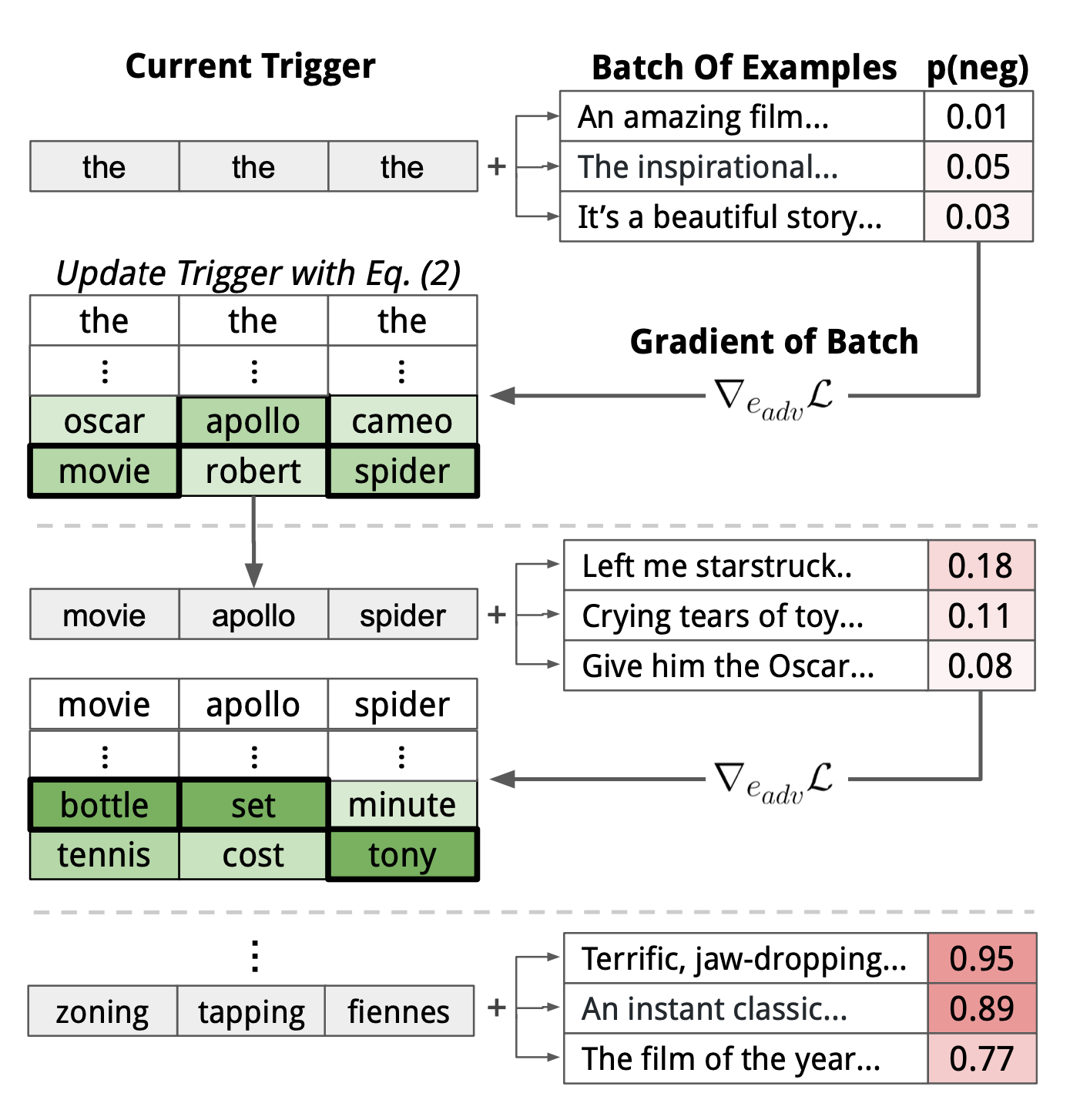
論文内では,このzonning tapping fiennesがトリガーとなって,モデルの分類を変化させます.具体的には感情分類タスクにおいて,元の文章(下図の上段落)「Visually imaginative, thematically instructive and thoroughly delightful, it takes us on a roller-coaster ride.」(視覚的にもテーマ的にも優れた作品で,お客様に楽しい体験を提供する)というのは,ポジティブな内容ですが,このトリガーによってネガティブと予測を操作することができます.

地味話ですが,元論文では実験結果と称して,具体的な文章がいくつも紹介されており,サブタイトル部分に「論文内のモデル出力は,現実では攻撃的なものを含みます」とオレンジ色で警告されていて面白かったです.
ARCA (自己回帰的ランダム座標上昇法)[Jones+ 2023] について見ていきましょう.座標降下法(Coordinate Descent:CD法)は,多変数の目的関数のうち,一つの変数を固定して他の変数を最適化することで問題を解く方法です.勾配を使う点は変わらないのですが,よくある通り,これを逆方向に更新することで(上昇させることで)攻撃します.
次の結果は,[Jones+ 2023] のものです.まず見てわかるのが,ARCAが最も優秀な攻撃手法であるようです.GBDAは他のと比べてやや原始的なアプローチと言えるのでしょう.

脱獄プロンプト
脱獄プロンプト(Jailbreak prompt)は,上記の二つと異なり,ブラックボックスなシナリオを想定しています.おおまかにはヒューリスティックな方法が多く,既存の結果の多くは人力によるものです.攻撃対象とされるのは,ChatGPTやClaudeなどの実用的なチャットボットであることが多いようです.
[Wei+ 2023] ではそのような現状の散逸的な知見を体系化しています.安全性を保つためのルールと衝突を誘導したり,安全性を保つためのデータの分布外(Out of Distribution : OoD)を利用するという二つの観点が示されていますが,今後はもっと増えていくかもしれません.
一つ目の具体例は,適当なロールプレイ(おばあちゃんプロンプト)や,特定の様式に従って答えさせるなどの方法が考えられます.二つ目の具体例は,Base64を使用するように求めたり,Payload Splittingが挙げられます.
これに関しては,正直なところ,毎日のように新しい方法が考えられ検証されているので完全な分類をするのは難しいようにも思います.
下の記事などを詳しく参照していただくのがよいのかもしれません.
難しいですが,下の記事で扱っている論文[Chowdhury+ 2024]の中では,脱獄プロンプトとプロンプトインジェクションは区別されているようです.日常会話の中では意識して区別することはなかったので,これは意外でした.
その他の動向
研究の方向として,モデルの内部機序から探るという可能性がありえると思います.例えば,Attention Headを見るという方法がありえるようです [Zhou+ 2024].Attention Headの解析は,以前の論文読みのなかで書いたように,機械論的解釈性(Mechanical Interpretability)のトピックの一つです.Headごとに特有の機能があることは様々な既存研究で指摘されている事実ですが,[Zhou+ 2024] では,Safety Headというモデルの安全性に関わるHeadの存在が明らかにされました.モデルへの敵対的攻撃に関する内部機序への研究は,例えば素子レベルや層レベルごとに,意外と数があるようです.
このような知見は当然,モデルを破壊することに利用できます.
さいごに
今回のまとめをしながら,モデルの機序説明に関して,実際に破壊するような研究から得られる知見の大きさを感じました.このまとめは,言語の離散性を考える過程で,雑にFGSMのことを思い出し検索をかけてみたところから始まりました.
実際に知らないことや,他の論文を読む中で知り得た知見と合致するところなどを垣間見ることができました.対象としているモデルはLLMであり,それに対する入力は言語(トークン列)なので,結局のところ,自然言語処理(NLP)や計算言語学の問題意識と自然に接続されます.それをセキュリティという方面から見ることが出来たのは、自分の視野を広げることができたと感じています.